
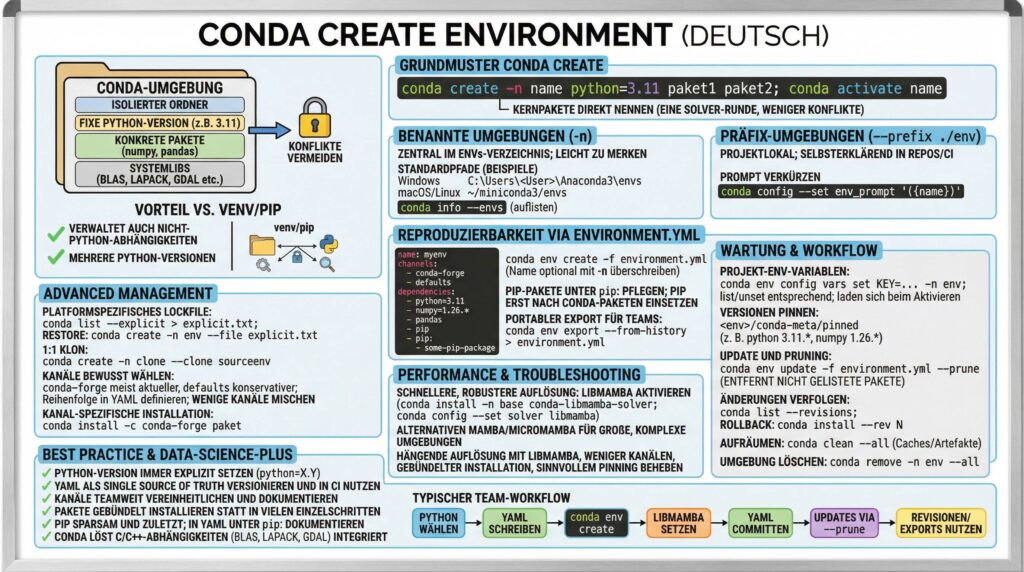
Dieser Leitfaden zeigt dir Schritt für Schritt, wie du saubere, isolierte Python-Umgebungen mit Conda erstellst, teilst, klonst und pflegst – von einfachen Setups mit conda create bis hin zu professionellen Workflows mit environment.yml, Lockfiles, Kanalmanagement und Solver-Tuning. Der Fokus liegt auf Reproduzierbarkeit, Wartbarkeit und Performance. Das Keyword conda create environment wird dabei kontextbezogen erläutert, damit du es nachhaltig in deinen Tooling-Alltag integrieren kannst.
Grundprinzip: Isolierte Umgebungen für konfliktfreie Projekte
Eine Conda-Umgebung ist letztlich ein Verzeichnis mit einer konkreten Sammlung von Paketen und einer festgelegten Python-Version. Jedes Projekt kann so seine eigene Laufzeit haben, ohne andere Projekte zu beeinflussen. Conda verwaltet nicht nur Python-Pakete, sondern auch Systembibliotheken, Nicht-Python-Software und mehrere Python-Versionen – ein Vorteil gegenüber rein Python-zentrierten Tools wie venv.
Merke: Jede Conda-Umgebung ist eine in sich geschlossene Laufzeit. Du kannst mehrere Projekte mit unterschiedlichen Anforderungen parallel betreiben – ohne Versionskonflikte.
- Isoliert: Pakete und Abhängigkeiten sind voneinander getrennt.
- Reproduzierbar: Mit
environment.ymlund Lockfiles kannst du Setups zuverlässig wiederherstellen. - Systemweit: Auch C/C++-abhängige Pakete und Tools werden verwaltet.
Schnellstart: Deine erste Umgebung in 60 Sekunden
# Leere Umgebung anlegen
conda create --name meinenv
conda activate meinenv
# Praktischer: Mit konkreter Python-Version
conda create --name meinenv python=3.11
conda activate meinenv
# Direkt mit Paketen
conda create --name meinenv python=3.11 numpy pandas scipy
conda activate meinenv
Damit nutzt du bereits das Grundmuster von conda create environment. Der Prompt zeigt nach der Aktivierung den Umgebungsnamen – ein visuelles Signal, dass du im richtigen Kontext arbeitest.

Methoden zur Erstellung: Von minimal bis ausgereift
1) Benannte Umgebungen
conda create --name research-ml python=3.10 scikit-learn jupyterlab
conda activate research-ml
Vorteil: Einfach zu merken, im Standard-envs-Verzeichnis zentral abgelegt.
2) Präfixbasierte Umgebungen (projektlokal)
# Umgebung direkt im Projektordner anlegen
conda create --prefix ./env python=3.11
conda activate ./env
Vorteil: Alles an einem Ort, ideal für Projekte mit klarer Ordnerstruktur. Du kannst in jeder Codebasis denselben Umgebungsordnernamen (z. B. env) verwenden, ohne Namenskollisionen zu riskieren.
3) Komplettpakete in einem Schritt installieren
conda create --name analytics python=3.9 scipy=1.10 astroid babel
Warum das sinnvoll ist:
- Weniger Konflikte: Conda löst Abhängigkeiten in einem Rutsch auf.
- Effizient: Eine Auflösung statt vieler einzelner Installationsschritte.
- Sofort lauffähig: Nach der Aktivierung hast du eine vollständige Umgebung.
Professionelle Reproduzierbarkeit mit environment.yml
Für Teams und CI/CD ist eine YAML-Datei der Standard. Sie wird versioniert, geteilt und ermöglicht kontrollierte Builds.
Beispiel: environment.yml
name: analytics
channels:
- conda-forge
- defaults
dependencies:
- python=3.11
- numpy=1.26
- pandas=2.1
- scipy
- pip
- pip:
- fastapi==0.110.0
- uvicorn[standard]==0.27.0
# Umgebung aus YAML erstellen
conda env create -f environment.yml
# Optional Namen übersteuern
conda env create -f environment.yml -n analytics-dev
Hinweis: Du kannst alternativ eine requirements.txt nutzen:
conda env create -f requirements.txt -n from-req
Exportieren – aber richtig
# Nur explizit installierte Pakete exportieren (ohne OS-spezifische Builds)
conda env export --from-history > environment.yml
Das --from-history-Flag erzeugt eine portablere Datei, ideal zum Teilen zwischen Windows, macOS und Linux.
Speicherorte: Wo Conda-Umgebungen liegen (und warum das wichtig ist)
Standardmäßig liegen Umgebungen im globalen envs-Verzeichnis. Für Projekte lohnt sich oft ein lokales Präfix.
| Plattform | Standardpfad für envs | Beispiel |
|---|---|---|
| Windows | C:\Users\<User>\Anaconda3\envs\ |
C:\Users\Max\Anaconda3\envs\analytics |
| macOS | ~/anaconda3/envs/ (oder ~/miniconda3/envs/) |
/Users/max/miniconda3/envs/analytics |
| Linux | ~/anaconda3/envs/ (oder ~/miniconda3/envs/) |
/home/max/miniconda3/envs/analytics |
Projektlokale Alternative via Präfix:
conda create --prefix ./envs/analytics python=3.11
conda activate ./envs/analytics
Du möchtest im Prompt trotzdem nur den Namen sehen? Konfiguriere das so:
conda config --set env_prompt '({name})'

Umgebungen klonen und 1:1 reproduzieren
Klonen
# Bestehende Umgebung klonen
conda create --name myclone --clone analytics
Nützlich, um eine bewährte Basis für ein neues Projekt bereitzustellen.
Explizite Spezifikation (Lockfile)
# Exakte Paketliste (inkl. URLs und Builds) erzeugen
conda list --explicit > explicit.txt
# Identische Umgebung (gleiche Plattform) wiederherstellen
conda create -n analytics-pin --file explicit.txt
Wichtig: Solche Spezifikationen sind plattformgebunden (z. B. linux-64, osx-64). Für plattformübergreifendes Teilen verwende conda env export --from-history.
Kanäle, Abhängigkeitsauflösung und Solver-Performance
Kanäle (channels)
- defaults: Von Anaconda gepflegt, solide Basisauswahl.
- conda-forge: Community-getrieben, sehr umfangreich und oft aktueller.
# Paket aus conda-forge installieren
conda install -c conda-forge numpy
In environment.yml definierst du die Reihenfolge:
channels:
- conda-forge
- defaults
Best Practice: Mische möglichst wenige Kanäle und definiere eine klare Reihenfolge. Viele gemischte Quellen erhöhen die Komplexität der Auflösung.
Schnellere (und oft robustere) Auflösung mit libmamba
# libmamba-Solver aktivieren
conda install -n base conda-libmamba-solver
conda config --set solver libmamba
Der libmamba-Solver beschleunigt die Abhängigkeitsauflösung in vielen Fällen deutlich und kann festhängende Auflösungen stabilisieren.
Alternative Implementierungen: mamba / micromamba
# mamba-Beispiel
mamba create -n analytics python=3.11 -c conda-forge
Mamba und Micromamba sind kompatible Werkzeuge mit fokussiertem Performance-Design. Sie sind besonders nützlich bei großen, komplexen Umgebungen.
Erweiterte Konfiguration: Umgebungsvariablen, Pinnen, Prompt
Umgebungsvariablen sicher an die Umgebung binden
# Variable setzen
conda env config vars set MY_KEY='secret-key-value' -n analytics
# Anzeigen
conda env config vars list -n analytics
# Entfernen
conda env config vars unset MY_KEY -n analytics
Beim Aktivieren werden diese Variablen geladen, beim Deaktivieren entfernt. Praktisch für API-Keys und projektspezifische Settings.
Pakete pinnen (Versionen fixieren)
Lege in ./conda-meta/pinned deiner Umgebung Regeln fest:
# Datei: <env>/conda-meta/pinned
python 3.11.*
numpy 1.26.*
pandas >=2.1,<2.2
So verhinderst du unbeabsichtigte Upgrades und bleibst stabil auf definierten Versionen.
Prompt anpassen (für Präfix-Umgebungen)
conda config --set env_prompt '({name})'
Ergebnis: Statt des kompletten Pfades siehst du nur den kurzen Umgebungsnamen.
Wartung und Updates: Revisionen, Pruning und Aufräumen
Umgebung aktualisieren
# Umgebung gemäß neuer environment.yml aktualisieren und ausmisten
conda env update -f environment.yml --prune
--prune entfernt Pakete, die nicht mehr in der YAML-Datei stehen. So bleibt deine Umgebung schlank.
Revisionen nachverfolgen und zurückrollen
# Historie anzeigen
conda list --revisions
# Auf eine frühere Revision zurücksetzen
conda install --rev 5
Nützlich, wenn ein Update dein Setup destabilisiert hat.
Aufräumen
# Cache und ungenutzte Artefakte entfernen
conda clean --all
Umgebung löschen
conda remove --name analytics --all
Cheatsheet: Häufige Aufgaben und passende Befehle
| Aufgabe | Befehl | Hinweise |
|---|---|---|
| Neue Umgebung erstellen | conda create -n envname python=3.11 |
Python-Version immer explizit setzen |
| Umgebung aktivieren | conda activate envname |
Bei Präfix: conda activate ./env |
| Pakete bei Erstellung mitinstallieren | conda create -n env python=3.11 numpy pandas |
Weniger Konflikte dank einmaliger Auflösung |
| Umgebung aus YAML erstellen | conda env create -f environment.yml |
Reproduzierbarer Team-Workflow |
| Export (portabler) | conda env export --from-history > environment.yml |
Keine OS-spezifischen Builds |
| Explizites Lockfile | conda list --explicit > explicit.txt |
Nur für identische Plattformen |
| Umgebung klonen | conda create -n clone --clone env |
1:1 Kopie |
| Solver beschleunigen | conda config --set solver libmamba |
Schnellere Auflösung |
| Revisionen anzeigen | conda list --revisions |
Transparente Änderungshistorie |
| Rollback | conda install --rev N |
Zurück zu funktionierendem Stand |
Benannte vs. präfixbasierte Umgebungen
| Aspekt | Benannter Ansatz (-n) |
Präfix-Ansatz (--prefix) |
|---|---|---|
| Speicherort | Zentral im envs-Verzeichnis | Im Projektordner (z. B. ./env) |
| Portabilität | Gut, aber Pfad nicht projektgebunden | Sehr gut, Projekt ist selbsterklärend |
| Prompt-Länge | Kurz (nur Name) | Oft lang (Pfad) – via env_prompt anpassbar |
| Team-Arbeit | Standard in vielen Teams | Beliebt in monorepos/CI |
Best Practices für nachhaltige Conda-Workflows
- Python-Version festlegen: Immer
python=X.Yangeben, um Kompatibilität sicherzustellen. - Pakete gebündelt installieren: Beim Erstellen direkt alle Kernpakete nennen.
- YAML statt Ad-hoc: Nutze environment.yml für Team- und CI-Setups.
- Export mit
--from-history: Erhöht die Portabilität über OS-Grenzen hinweg. - Solver auf libmamba umstellen: Beschleunigt die Abhängigkeitsauflösung spürbar.
- Kanäle klar definieren: Z. B. conda-forge vor defaults – und wenige Kanäle mischen.
- Pruning nutzen:
conda env update -f environment.yml --prunehält Umgebungen schlank. - Revisionen pflegen: Mit
conda list --revisionstransparent bleiben und rückrollfähig sein. - Pinning bei kritischen Projekten: Stabilität priorisieren.
- Pip nur gezielt: Wenn ein Paket nicht via Conda verfügbar ist, dann pip am Ende installieren (nach Möglichkeit innerhalb der Conda-Umgebung).
Projekt-Setup: Ein sauberes Beispiel
my-project/
├─ data/
├─ notebooks/
├─ src/
├─ env/ # Präfix-Umgebung (nicht committen)
├─ environment.yml # versionieren
├─ README.md
└─ .condarc # optional, z. B. env_prompt-Konfiguration
Einrichtung:
conda env create -f environment.yml
conda activate ./env # falls als Präfix erstellt
# oder
conda activate my-project-env
Fehlerbehebung: Typische Stolpersteine und Lösungen
- Auflösung hängt fest: Wechsle auf
libmamba, reduziere Kanäle, installiere Pakete gebündelt, prüfe Versionsbeschränkungen. - Lange Prompts bei Präfix:
conda config --set env_prompt '({name})'. - Konflikt zwischen Pip und Conda: Bevorzuge Conda-Pakete. Falls pip nötig ist, installiere es zuletzt und dokumentiere die Pip-Pakete in der YAML unter
pip:. - OS-spezifische Builds in Exporten: Nutze
--from-historystatt eines vollständigenconda env exportohne Flag. - Unklare Paketquellen: Definiere
channelsexplizit in der YAML. - Alte Artefakte/Cache:
conda clean --allregelmäßig einsetzen.
Praxisnaher Workflow von Null bis Team-Sharing
- Projektziel klären und Python-Version wählen (z. B. 3.11).
- YAML schreiben (Name, Kanäle, Pakete; Pinning falls nötig).
- Umgebung erzeugen:
conda env create -f environment.yml. - Solver-Optimierung:
conda config --set solver libmamba. - Konfiguration teilen: YAML in Git committen.
- Aktualisieren: Bei Änderungen
conda env update -f environment.yml --prune. - Revisionskontrolle: Bei Problemen
conda list --revisionsund ggf.conda install --rev N. - Export für andere Systeme:
conda env export --from-history.
Warum Conda (auch) für Nicht-Python-Abhängigkeiten überzeugt
Viele wissenschaftliche Pakete benötigen systemnahe Bibliotheken (z. B. BLAS, LAPACK, GDAL). Conda löst solche Abhängigkeiten integriert auf und macht separate Systeminstallationen oft überflüssig. Das reduziert Komplexität und erhöht Reproduzierbarkeit, insbesondere in Data-Science- und ML-Projekten. Genau hier spielt conda create environment als robustes Fundament seine Stärken aus.
Zusammenarbeit im Team: Standards, die Skalieren
- YAML-first: Jede Änderung an Paketen in Pull Requests abbilden.
- CI-Builds: Umgebungen in CI mit
conda env create -f environment.ymlaufsetzen. - Kanäle vereinheitlichen: Teamweit dieselbe
channels-Reihenfolge. - Dokumentation: Lesezeichen in README (z. B. wie aktivieren, wie updaten, wie prunen).
- Lockfiles (optional): Für produktionskritische Deployments per
conda list --explicitplattformspezifisch festschreiben.
Leitlinien zur Paketwahl und Kanalstrategie
Bevor du blind installierst, lohnt ein kurzer Blick auf die Quelle:
- Suche zentrale Pakete bevorzugt in conda-forge, besonders wenn du aktuelle Versionen brauchst.
- Reduziere Mischkanäle, um Auflösungskonflikte zu vermeiden.
- Wenn ein Paket nur via Pip verfügbar ist, integriere es klar in
pip:unter dependencies in deiner YAML.
# Paketverfügbarkeit prüfen
conda search package-name -c conda-forge
Fazit
Mit Conda baust du stabile, reproduzierbare und wartbare Umgebungen, die weit über reine Python-Pakete hinausgehen. Entscheidend sind: explizite Python-Versionsangaben, gebündelte Paketinstallationen, eine saubere environment.yml als Single Source of Truth, Export mit --from-history für Portabilität und ein schneller, robuster Solver wie libmamba. Nutze benannte oder präfixbasierte Umgebungen je nach Projektzuschnitt, sichere kritische Versionen per Pinning ab und pflege deine Setups mit Pruning, Revisionen und regelmäßigen Aufräumaktionen. So setzt du conda create environment im Alltag effektiv ein – von lokalen Notebooks bis hin zu teamweiten CI/CD-Pipelines.
FAQ: Häufige Fragen zu Conda-Umgebungen
1) Worin unterscheidet sich Conda von venv und Pip?
Conda verwaltet neben Python-Paketen auch Nicht-Python-Abhängigkeiten, Systembibliotheken und sogar mehrere Python-Versionen. venv isoliert nur die Python-Site-Packages, pip ist ein reiner Python-Paketmanager. Für Datenwissenschaft und wissenschaftliches Rechnen ist Conda oft die robustere Wahl.
2) Soll ich conda-forge oder defaults verwenden?
Beides ist möglich. conda-forge ist meist aktueller und umfangreicher, defaults konservativer. Definiere eine klare Reihenfolge in channels (z. B. zuerst conda-forge) und vermeide viele gemischte Quellen.
3) Wie teile ich Umgebungen zwischen Windows, macOS und Linux?
Exportiere mit conda env export --from-history. Das erzeugt eine portablere environment.yml ohne OS-spezifische Builds. Achte außerdem auf Kanalkonsistenz und klare Versionsangaben.
4) Kann ich Pip-Pakete in Conda-Umgebungen nutzen?
Ja. Am besten zuerst alle verfügbaren Pakete via Conda installieren und danach fehlende Pakete per Pip ergänzen. Dokumentiere Pip-Pakete in der YAML unter pip:. Beispiel siehe oben.
5) Wie mache ich die Auflösung schneller und stabiler?
Stelle auf den libmamba-Solver um: conda install -n base conda-libmamba-solver und conda config --set solver libmamba. Installiere Pakete gebündelt, reduziere die Kanalvielfalt und setze Versionsbeschränkungen sinnvoll ein.
6) Wie sichere ich kritische Versionen gegen Upgrades ab?
Nutze das pinned-File im Ordner conda-meta deiner Umgebung (z. B. numpy 1.26.*). Alternativ kannst du in der YAML feste Versionen vorgeben.
7) Wie kann ich auf einen stabilen Stand zurückrollen?
Mit conda list --revisions siehst du die Historie. Rolle via conda install --rev N auf einen früheren, funktionierenden Zustand zurück.
8) Wie entferne ich nicht mehr benötigte Pakete?
Aktualisiere per conda env update -f environment.yml --prune. Das entfernt alles, was nicht mehr in der YAML gelistet ist. Zusätzlich hilft conda clean --all beim Aufräumen von Caches.
9) Wie finde ich alle bestehenden Umgebungen?
Mit conda info --envs erhältst du eine Übersicht der verfügbaren Umgebungen samt Pfaden.
10) Was ist der Unterschied zwischen benannten und präfixbasierten Umgebungen?
Benannte Umgebungen leben zentral im envs-Verzeichnis und sind schnell zu aktivieren. Präfixbasierte liegen direkt im Projektordner, was die Zuordnung erleichtert und Projekte selbsterklärend macht. Den Prompt kannst du für beide Varianten anpassen.